Overview
Paper: Discovering Mechanisms in Tokenized Graph Transformers (ICML 2026 Workshop on Mechanistic Interpretability)
Although the field of mechanistic interpretability has made significant progress in large language models (particularly natural language reasoning), the techinques have yet to be applied to a more general class of data structures, such as graphs. In our recent paper “Discovering Mechanisms in Tokenized Graph Transformers”, we use various mechanistic interpretability techniques to analyze the inner workings of a graph transformer trained on a synthetic graph dataset with TokenGT-like tokenization. By nature, graphs provide rich and complex relational structures, and therefore we expected that the model would have learned to identify nodes and compose them in task-specific ways. By training the model to solve three tasks (i.e., degree counting, ring membership, and shortest path distance), we identify several key mechanisms that the model uses to solve the task, including early degree-like computation, task-specific compositions, and node ID identification.
In this post, we present a series of interactive demos that provides a visual and intuitive understanding of several key points from the paper, as well as some additional insights that were not included in the paper.
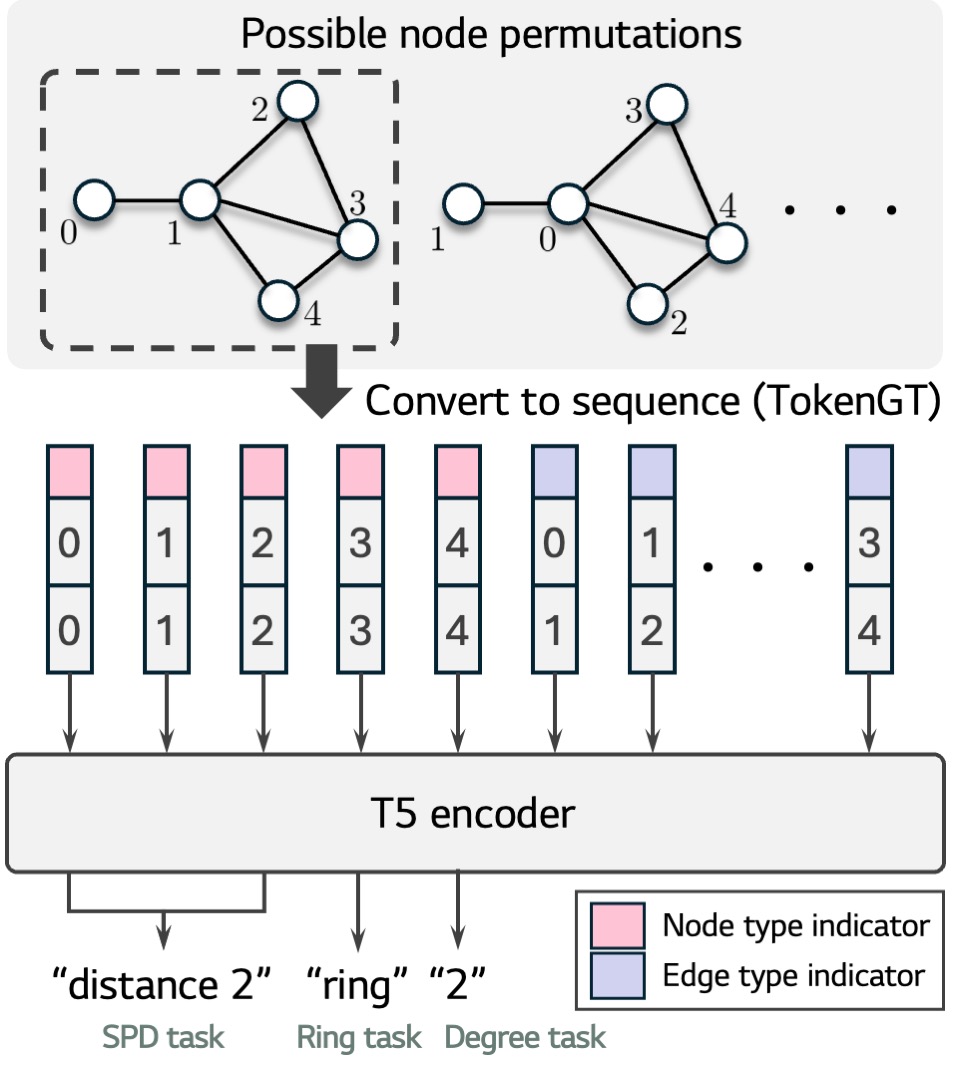
Setup at a glance
The figure below shows how the graph is represented, and how the model is trained to solve the three tasks.
Degree direction steering
One of the most prominent mechanisms that we discovered is the existance of degree direction $\hat{w}_{\mathrm{deg}}^{(0)}$ at the residual stream in the early layers of the model. Counting the degree (i.e., the number of neighbors) of a node is a fundamental structural feature while being one of the simplest information to extract from a graph.
Naturally, encoding the degree information in the early layers of the model naturally solves the degree counting problem. In this demo, we perform an intervention experiment where we explicitly add $\alpha \hat{w}_{\mathrm{deg}}^{(0)}$ to the residual stream at the L0-mid position for the degree counting model.
If you play with the slider, you will see that the model’s predictions are steered along the degree direction. In particular, when you push $\alpha$ to a higher value, the model will start to predict higher (and wrong) degrees, and vice versa for lower values of $\alpha$. This shows that the model’s predictions are indeed sensitive to the degree direction, and that the model has learned to encode degree information in the early layers.
Ring membership L1 ablation
For the ring membership task, we found that the model assumes all nodes to be a ring member by default. In this demo, we will perform a zero ablation of the entire L1.
You can see that when we ablate L1, the model starts to produce incorrect predictions. Notice that all of the wrong predictions are for the non-ring nodes, which indicates that the model initially assumes all nodes to be a ring member, and that the L1 provides non-ring evidence to correct the model’s predictions.
Shortest-path routing
This demo shows the L2:H2’s routing behavior for the shortest path distance task for a specific graph example. Although not always the case, we found that this head often acts as a BFS-parent pointer head, and is responsible for selectively copying the BFS-parent node’s information to the current node. This is a crucial step in the model’s computation, as it allows the model to understand the pairwise relationships between nodes in the graph, and to compute the shortest path distance between them.
QK identifier matrices
This demo demonstrates how the model’s ID matching mechanism works. For this demo, we only show the QK matrices when the ID vectors are used as queries and keys, which does not showcase the full routing behavior of the model but is sufficient to show the ID matching pattern. The QK values show that the model has learned to match the IDs of the nodes by assigning much higher scores to the same ID. Essentially, it creates a soft identity matrix, which allows the model to be much more flexible in matching the IDs even when the number of ID vectors used during training is larger than the dimension of the ID vectors.
Attention & identifier matching
This is a straightforward visualization of the attention maps for the trained models. The attention maps below definitely show that there exists an intricate structure in the model, which routes node and edge information in a task-specific manner. This structure was one of the primary motivations for us to investigate the model’s inner workings in a mechanistic way.
However, after we wrote the majority of the paper, we realized that most of the seemingly promising attention patterns were actually not causally active in the model’s inference. This suggests that using attention maps to interpret graph transformers requires caution and requires causal validation. We included a detailed discussion on this topic in the appendix of the paper.